
GROUP BY 和 HAVING 的用法
前言
- GROUP BY 是分组查询, 一般 GROUP BY 是和聚合函数配合使用。
- group by 有一个原则,就是 满足
SELECT子句中的列名必须为分组列或列函数。 - 列函数对于 group by 子句定义的每个组各返回一个结果。
- HAVING 通常与 GROUP BY 子句一起使用
- WHERE 过滤行,HAVING 过滤组
- 出现在同一 sql 的顺序:WHERE -> GROUP BY -> HAVING
使用
三张数据表-学生表(student_id、name、age、sex)、课程表(course_id、name)、成绩表(student_id、course_id、score)
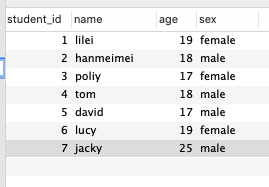
- 学生表(student_id、name、age、sex)
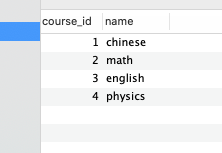
- 课程表(course_id、name)
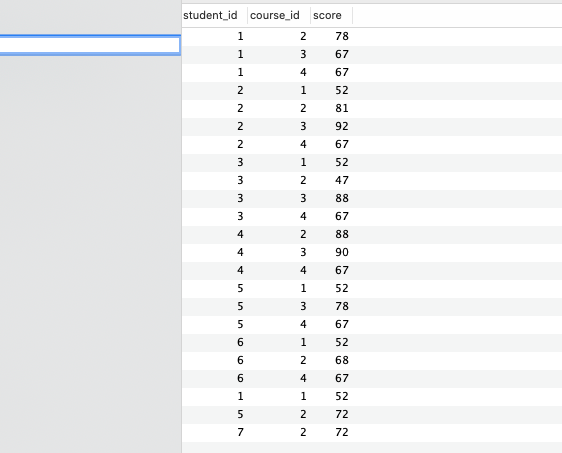
- 成绩表(student_id、course_id、score)
GROUP BY
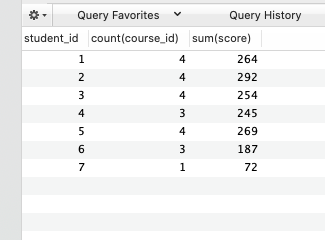
- 查询所有同学的学号、选课数、总成绩
select student_id, count(course_id), sum(score)
from score
group by student_id;
列函数对于 group by 子句定义的每个组各返回一个结果。 如果用 group by,那么你的 select 语句中选出的列要么是你 group by 里用到的列,要么就是带有 sum min count 等函数的列
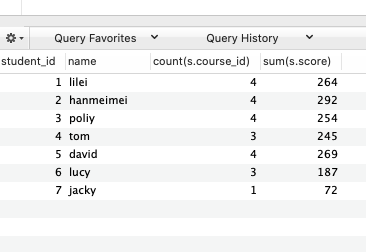
- 查询所有同学的学号、姓名、选课数、总成绩
select s.student_id, stu.name, count(s.course_id), sum(s.score)
from score s, student stu
where s.student_id = stu.student_id
group by s.student_id;
group by 里出现某个表的字段,select 里面的列要么是该 group by 里面的列,要么是
别的表的列或者带有函数的列
HAVING
- 查询平均成绩大于 60 分的同学的学号和平均成绩
select student_id, avg(score)
from score
group by student_id
having avg(score) > 60
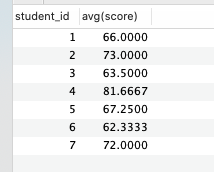
having 必须要在 group by 之后,不然会报错。如果省略了 group by 语句,having 子句就跟 where 语句一样
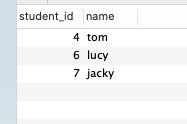
- 查询没有学全所有课的同学的学号、姓名
select stu.student_id, stu.name
from student stu, score s
where stu.student_id = s.student_id
group by s.student_id
having count(*) <
(
select count(*) from course
)
- 取出 student_id 为 1 的学生的成绩情况
select s.student_id, c.name, s.score
from score s, course c
where s.course_id = c.course_id
having s.student_id = 1

where子句的作用是在对查询结果进行分组前,将不符合 where 条件的行去掉,即在分组之前过滤数据,条件中不能包含聚组函数,使用 where 条件显示特定的行。having子句的作用是筛选满足条件的组,即在分组之后过滤数据,条件中经常包含聚组函数,使用 having 条件显示特定的组,也可以使用多个分组标准进行分组。